Lecture 05 Storage Models & Compression
Database Workloads
今天我们会粗略的讨论一下数据库的分类
-
On-Line Transaction Processing(OLTP) -- 在线事务处理
这些应用场景 涉及从外部世界摄取新数据 并同时为大量用户提供服务
当你访问Amazon网站时,你会浏览产品 点击商品 并将其加入购物车 进行购买
也或者可能会登录账户信息 更新邮寄地址或支付信息
这些都被视为 OTP stype 因为您正在对数据库的一小部分子集进行更改
通义千问:OLTP是一种数据库系统设计,旨在支持和管理事务导向的应用程序。这类系统主要用于实时业务操作中,如银行交易、电子商务网站上的购买行为等。其主要特点是能够快速响应用户请求,确保数据的一致性和完整性,并且可以同时为大量用户提供服务
-
On-Line Analytical Processing(OLAP)
运用的场景是想执行那些能够从整个数据集中提取或推理出新信息的查询
example:在宾夕法尼亚周的周六 气温超过80度时 销量排名第一的商品
一般以读取为主
-
Hybrid Transaction + Analytical Processing(HTAP)
OLTP+OLAP 与其让所有交易数据提取出来 放入一个独立的数据仓库 在那里进行分析 或许可以再数据流入时 直接做一些分析
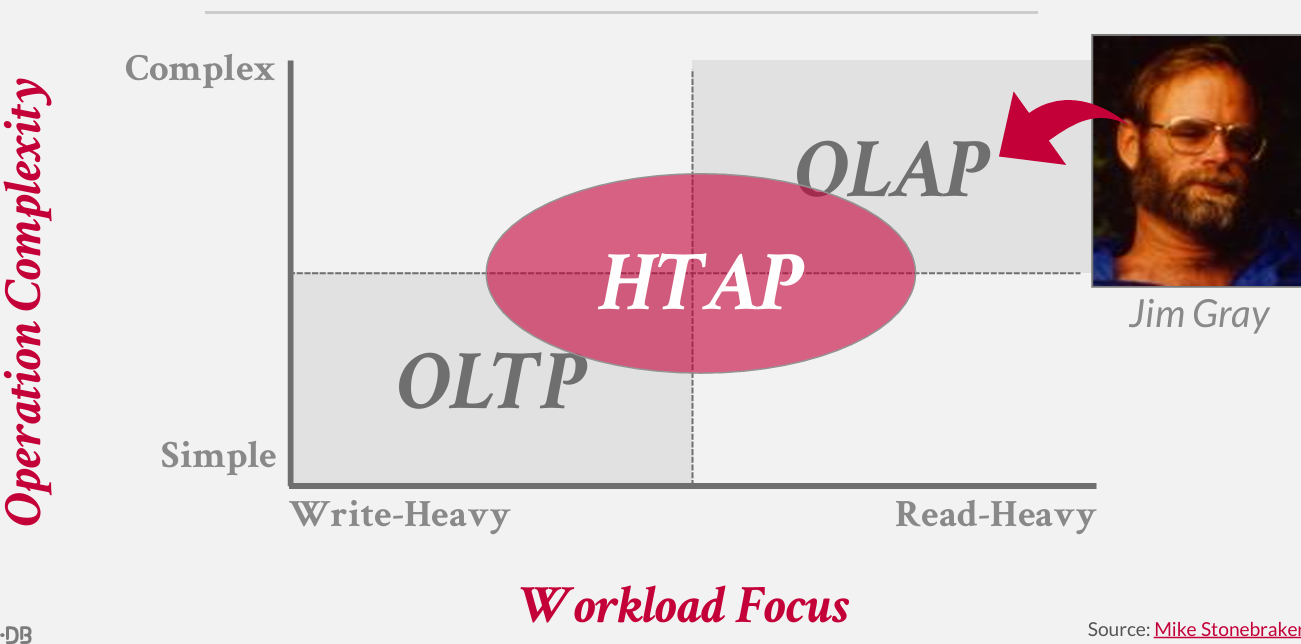
x轴表示工作负载 是读取密集型还是写入密集型
y轴表示 查询的复杂程度
在前两讲讨论的东西 对 OLTP有利 对OLAP不友好 -- 涉及一种适合OLAP的存储方案
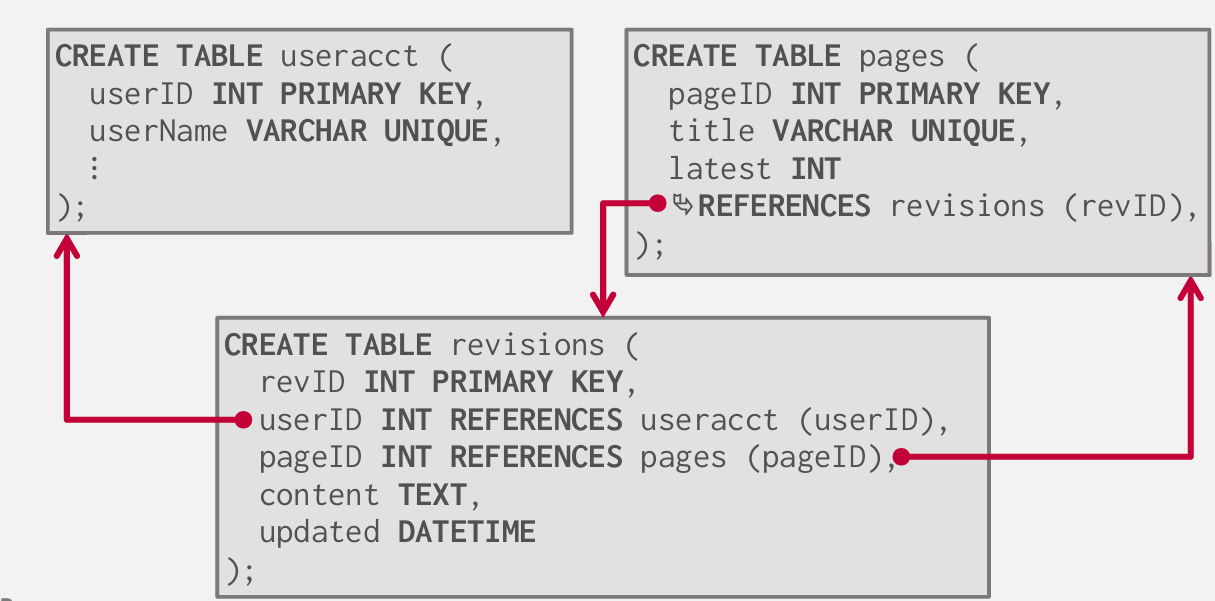
真实数据库例子 -- 这大致是维基百科数据库的样子 它运行了一个MediaWiKi的软件 基于MySQL和PHP
OLTP -- 其实就是涉及大量的简单的基础查询

对于OLAP 进行更复杂的操作
storage models
is 数据库系统将如何物理层面上组织磁盘和内存中的元组,以及他们相对于其他元组以及自身属性的关系
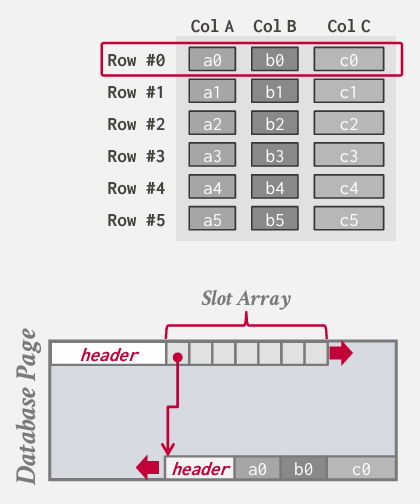
直到现在 我们还是假设的是一个元组的所有属性都是连续的 --- 成为 行存储
但这对于OLAP来说 可能并非是最佳选择
我们必须讨论这个的原因在于 当前市场或数据库领域中 行存储系统和列存储系统之间的区分
- 行存储 希望用于 OTP
- 列存储 希望用于OLAP
我们要探讨的三种storage model为:
- N-array Storage Model(NSM): row store
- Decomposition Storage Model(DSM): 分解存储模型 -- column store
- Hybrid Storage Model: Partition Attributes Across(PAX): common for column stores
NSM
事实上 课程一直在讲的就是row Storage
这种设计更适合OTP系统的原因是因为OTP应用大多数查询只访问单个记录
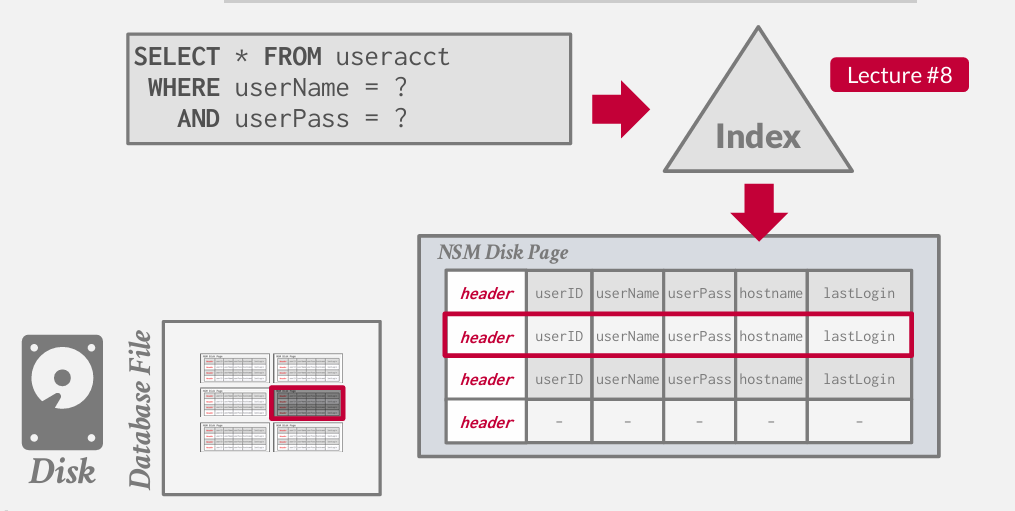
维基百科的例子是怎么运行的?
假设有一个查询 某人想要登录
SELECT * FROM useracct WHERE userName = ? AND userPass = ?
我们忽略如何实际找到特定用户所需的数据
假设存在某种索引 可能是哈希表 b+树
但 会告诉 record id 和 offset偏移量
至于为什么通过where username =? 就找到了这条记录 这是索引的作用 下周的问题
插入操作也是一样
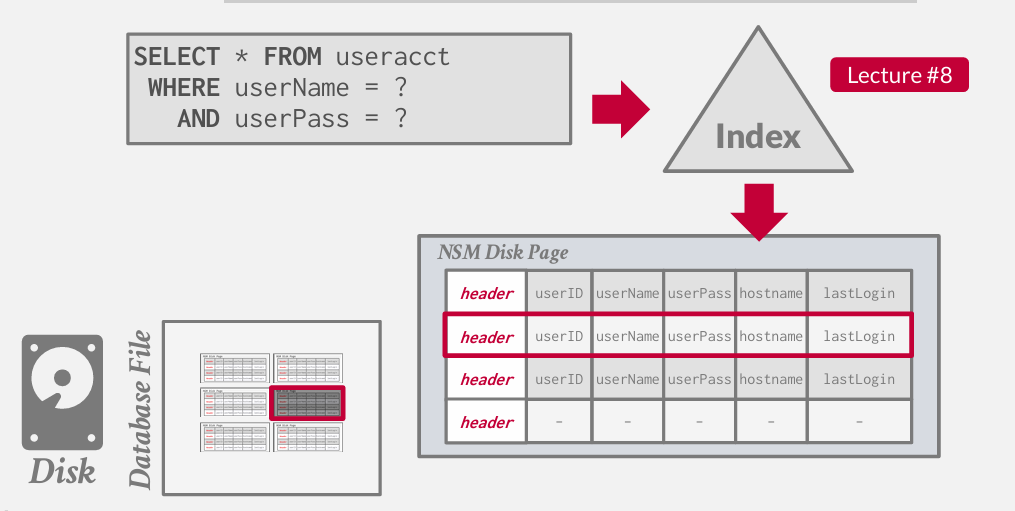
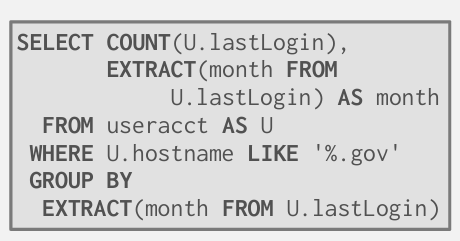
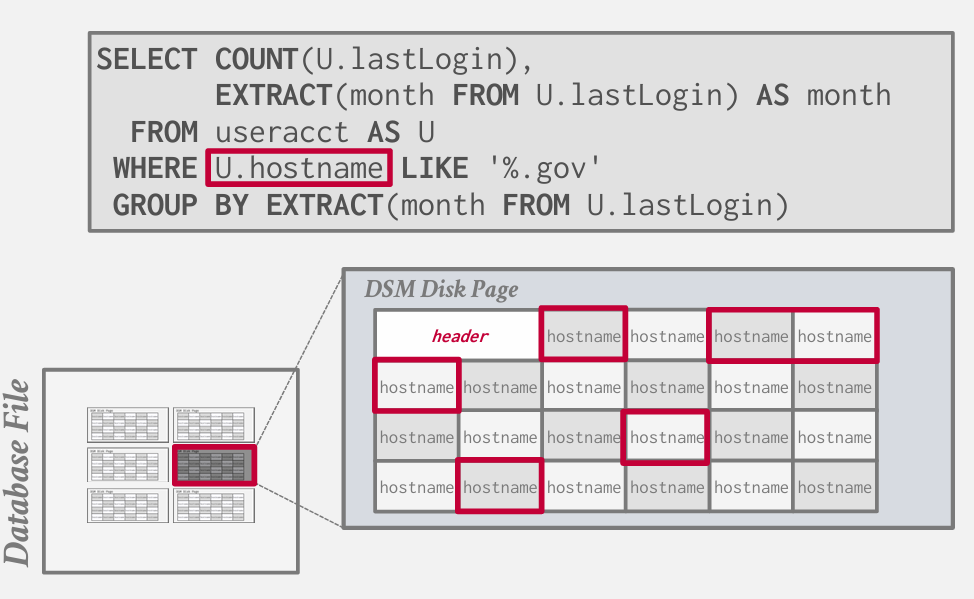
如果现在我想找出以.gov 为后缀的域名主机名 统计每月登记的次数 并排序
我需要扫描所有的page

假设对其中一页的扫描 显而易见 我们只查询了hostname 和 lastLogin 红框框的是无用数据
我只能读入整个page 但是一些无效IO
而且在内存的不同地方 跳转 进行扫描 会变慢
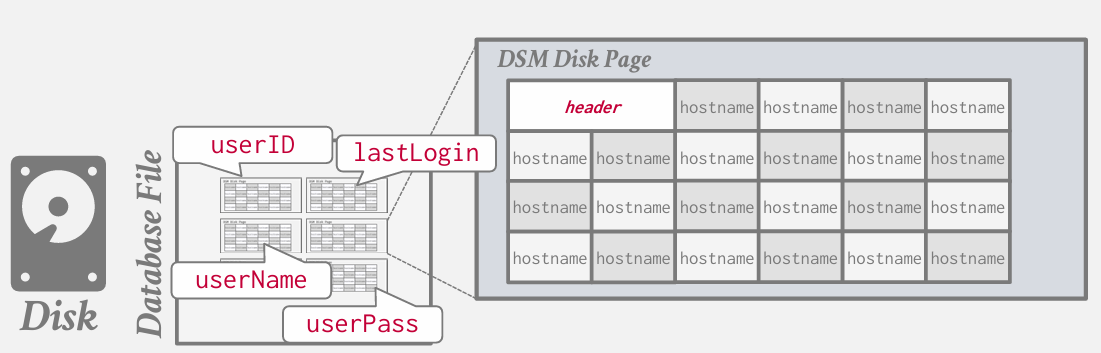
压缩问题 但在目前情况下若想减少数据量或在单个页面内打包更多数据 我们难以获得良好的压缩比率 因为给定表的所有属性 他们杂乱无章的堆砌在那个页面上
因为存的时候不是像图中看到的这样规矩 是顺序存储的 而且userName不一样长 password加密以后可能一样长 所以每次去找hostname只能先读取header 找偏移量
DSM
一种代替方法是DSM 列式存储 分解存储模型
这里的思路是不将单个元组的所有属性存储在一页中 而是对于所有元组 在单个页面上存储单个属性
这对于OLAP查询来说是非常理想的 因为它会对表中的一部分属性进行全表扫描
但其实SQL建表 时的声明还是那样 事实上也无需那么关心 运行在行存储还是列存储系统上
同一个SQL 查询 也会得到相同的答案
这是 研究 database system 需要关注的事情
在列存储中 我们的职责就是接收数据 然后分为独立的列 并在需要重新生成结果的时候再重新组合起来
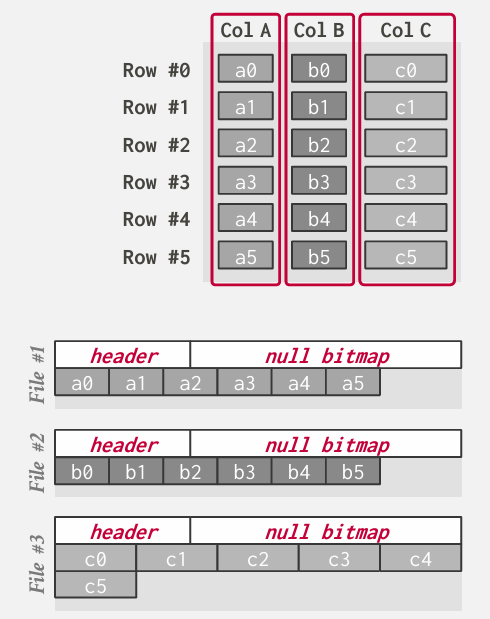
事实上这些不同文件的元数据开销实际上远小于行存储 因为我们无需跟踪所有额外的 每一列是否为空的信息 关于偏移量 等等的信息
其实update会变得蛮麻烦的 内存压力也是蛮大的
通常解决这个问题的方法是 这些系统会有一个行存储缓冲区 该缓冲区是日志结构的 如果更新 会将其应用到行部分 然后定期把他们合并到列存储
Oracle采用了不同的方法 行存储为视为是数据库的主要存储位置 但随后会复制表位列存储格式 并保持列存储的更新
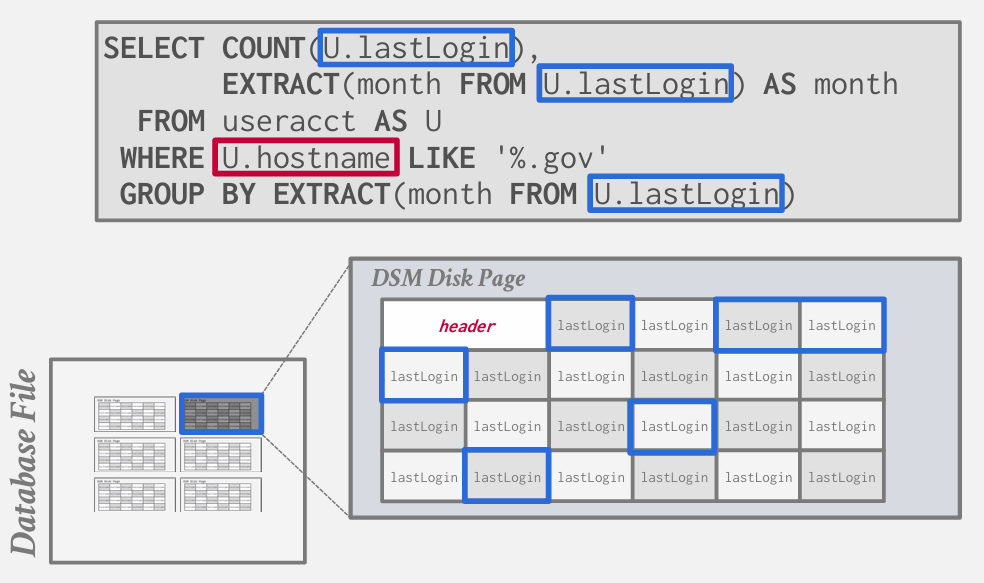
在这个例子中 是先去取 hostname 然后去取lastLogin页面 那么到底是怎么匹配的呢?
有两种方法
- Choice 1:Fixed-length Offsets
Choice 2:Embedded Tuple Ids
最常见的方法就是固定长度偏移 Fixed-length Offsets -- 这意味着并不是通过槽位号来识别 而是通过识别唯一元组来进行标识--而对于元组的唯一表示符 就是表中的偏移量
也就是说 如果我在某一列的偏移量为3的位置 我就知道如何跳转到另一列偏移量同样为3的位置 但是这只适用于定长 变长字段会打破这个(后面讲如何处理)
传统方法是通过嵌入式ID来实现 -- 对每一个值 都拥有一个唯一的元组标识符 -- 就是红色的这个
此外 还有一个再此没有展示的索引结构 针对给定的记录id 和 特定列 会指示跳转到何处 不太常见
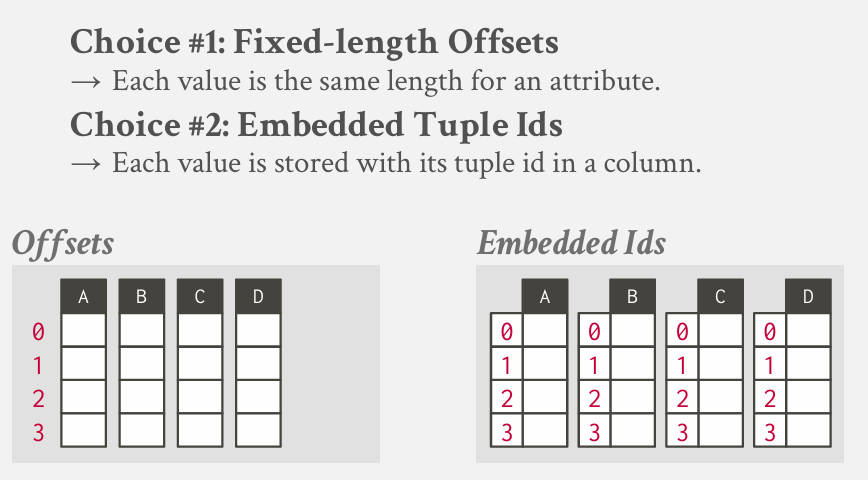
现在面临的问题就是如何将变长值 变为 定长值
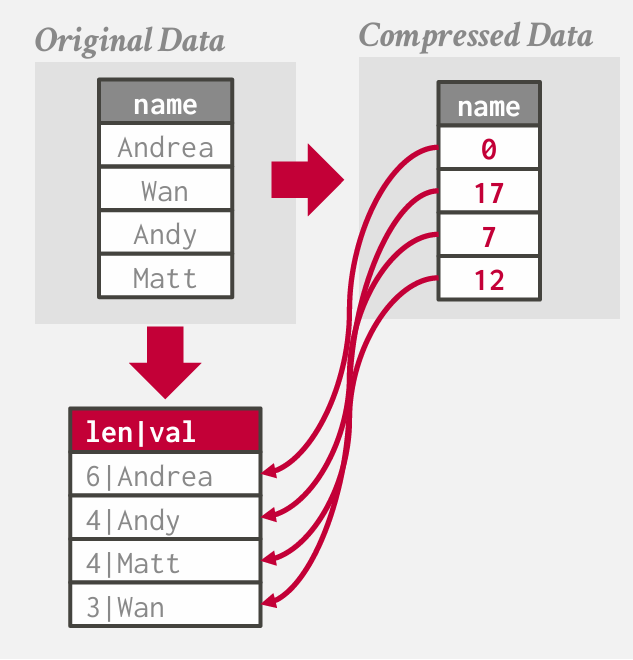
dictionary compression 字典压缩
将某些变长值替换为一个整数码 该码具有固定长度 通常为32位 我们可以利用它来进行字典码上的某些谓词操作 如果匹配到所查找的内容 进行查找获取实际值
例如,如果某一列包含了多个重复的城市名称,那么就可以将这些城市名称存储在一个字典中,并用一个对应的唯一ID来替代实际的城市名称存储在主数据集中
embedded tuple Ids
使用嵌入式元组 ID。在这里,对于列中的每个属性,DBMS 都会存储一个元组 ID(例如:主键)。然后,系统还将存储一个映射,以告知它如何跳转到具有该 id 的每个属性。请注意,此方法具有较大的存储开销,因为它需要为每个属性条目存储一个元组 ID

- 1970s 公认的第一个有关系存储系统的文献提案 -- 但事实上不是数据库 更像是一个文件管理
- 1980s 有一篇论文实际勾勒出了分解存储模型理论特性的蓝图
- 1990s 首个商业化列存储系统 SybaseIQ --但事实上并非完全成熟的数据库系统 更像是一个查询加速器 类似Oracle的情况 行存储-》列存储
- 2000s 出现了三个关键系统 才是真正起飞
- 2010s 好多数据库系统都在做这个事儿 而且出现了两种开源文件 基于列的开原文件格式
事实上 我们在查询的时候 where 后面可能有好多条件 我们要同时操作查看多个列 在扫描一列的同时 还要获取另一列的数据 这会变得比较繁琐
所以我们想做的是使得 共同使用的属性在disk上彼此相对靠近 同时 列存储
这就是PAX模型的含义
PAX storage model
大多数 所谓的列存储 其实都是pax storage model
PAX storage model的思想是 -- 与其 为某一列都单独创建一个独立的文件 -- 把所有的tuple分成块 形成行组 每一个行组 利用类似列存储的方式 将每一列的数据放在一起
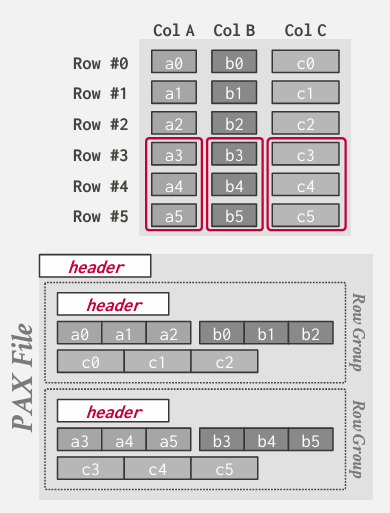
加入有一个同时访问a列和c列的where子句 获取这项行组的页面的时候 访问的数据就彼此相邻
有一个global header: 里面包含着行组偏移量的directory
每一个行组也有header 包含着所有内容的元数据
这就是Parquet Orc的工作原理
这种方式 不会像行存储一样 引入无用数据 因为有header 会告诉属性的偏移 也不会像列存储那样数据不相邻
Database Compression
跳过数据是列存储技术所擅长的--避免了读取不需要的属性 -- 但压缩可以使每次获取的页面 获得更多的元组
所谓的压缩 就是 将变长的数据 压缩为 定长的数据 比如一兆大小的string 压缩为 32bit的数字 我希望可以长时间的保持压缩状态 仅在需要内容的时候解压缩
在数据库系统中 任何压缩方案最关键的一点是 必须保持采用无损压缩方案
我们究竟想要压缩什么?
根据Compression Granularity:
- Choice #1: Block-level →Compress a block of tuples for the same table.
- Choice #2: Tuple-level →Compress the contents of the entire tuple (NSM-only).
- Choice #3: Attribute-level →Compress a single attribute within one tuple (overflow). →Can target multiple attributes for the same tuple.
- Choice #4: Column-level →Compress multiple values for one or more attributes stored for multiple tuples (DSM-only)
Naive Compression

MySQL是怎么实现的? MySQL InnoDB
由于访问数据需要解压缩压缩数据,因此这限制了压缩方案的范围。如果目标是将整个表压缩成一个巨大的块,那么使用简单的压缩方案是不可能的,因为每次访问都需要压缩/解压缩整个表。因此,由于压缩范围有限,MySQL 将表分成更小的块。
其工作原理是 当你所有的页面被写入磁盘时 他们将被压缩成一个页面大小 该大小将是 4 或 2 的倍数 上限位8KB
每一页都有一个被称为 mod log的头部的部分 类似于之前提到的行起始结构 可以在不先解压缩页面的情况下 进行多次写入和更改
如果只是写入 或者更改 那么无需解压 只需要写入修改日志(mod log)
某些情况可以在修改日志上进行读取 也不用解压
如果真的需要解压 那么就会解压 后 以 常规16KB 存储在内存的缓冲池中
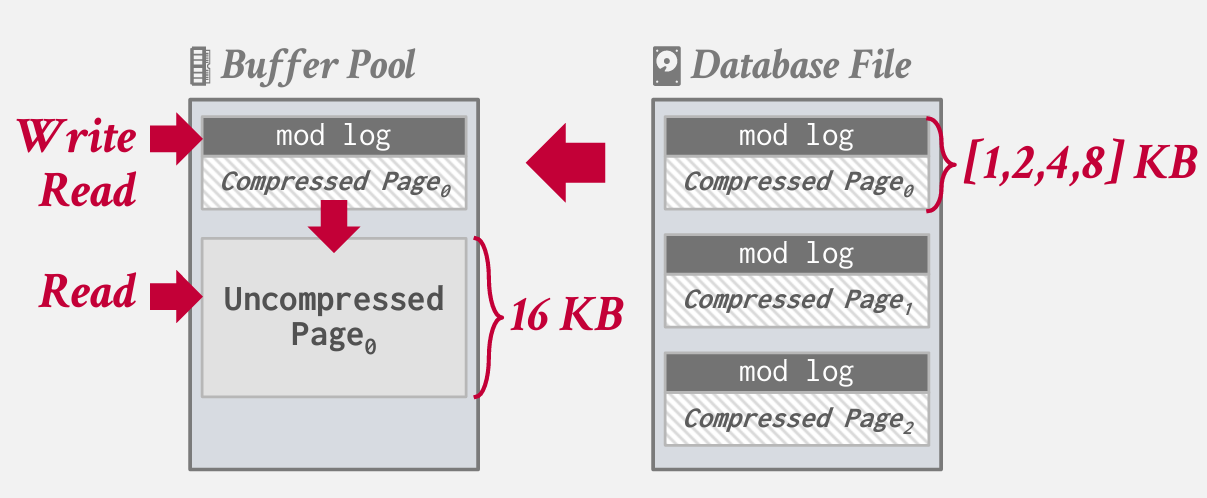
这是个不错的方法
但是有一定的挑战 MySQL是一个行存储结构 所以他只能压缩整个内容 没法向列存储结构那样 压缩列
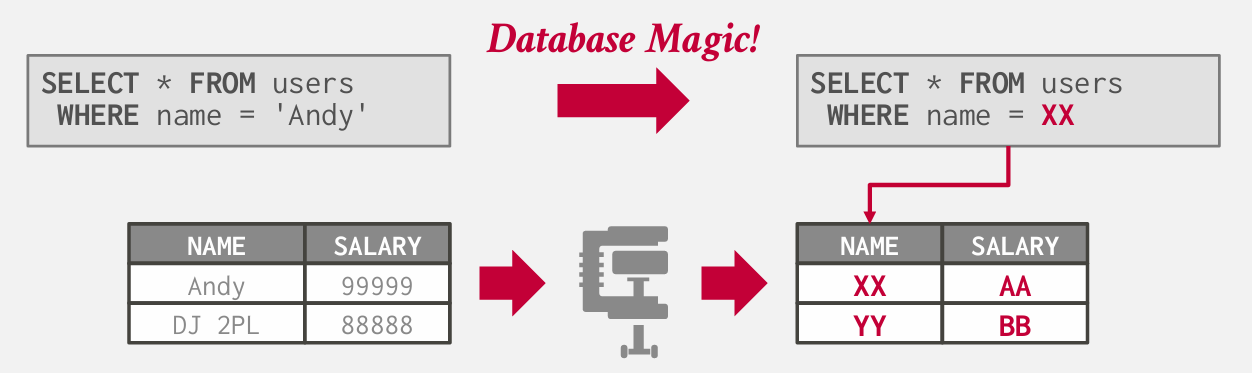
压缩后或许只需要查找压缩后的常量
column-level
能采用的算法:

字典压缩式大多数系统的选择
在字典压缩后 还可以对字典本身或者已编码的字典值 应用其他压缩方案 从而得到更深层次的压缩效果
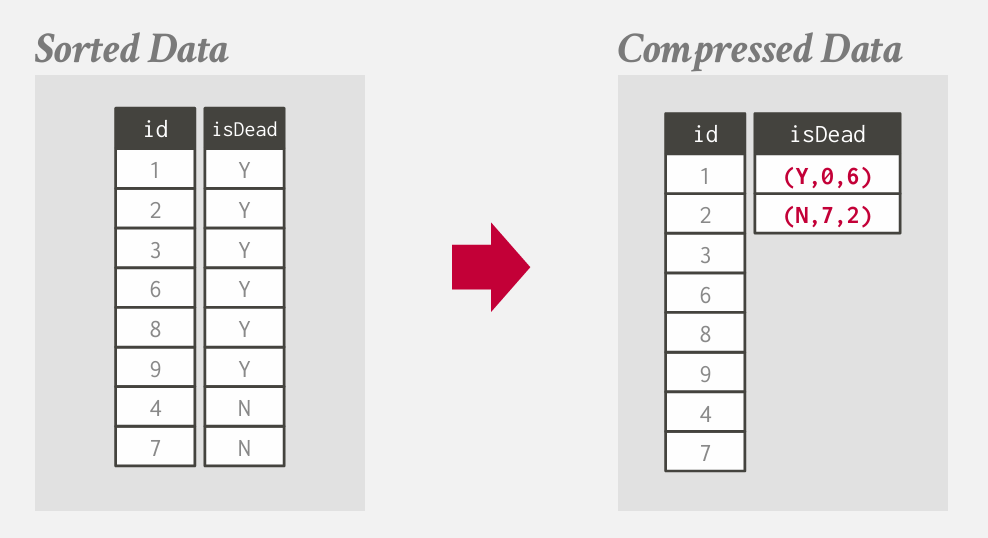
run-length Encoding
如果有相同的数值 不必为每个元组重复存储 而是存储一个压缩摘要 指出特定偏移量处 该值出现的次数
将单个列中相同的值压缩为三元组
- 属性值
- 列段中的起始位置
长度 几个 The numberof elements in the run
一般会对列进行智能排序 来增加压缩机会
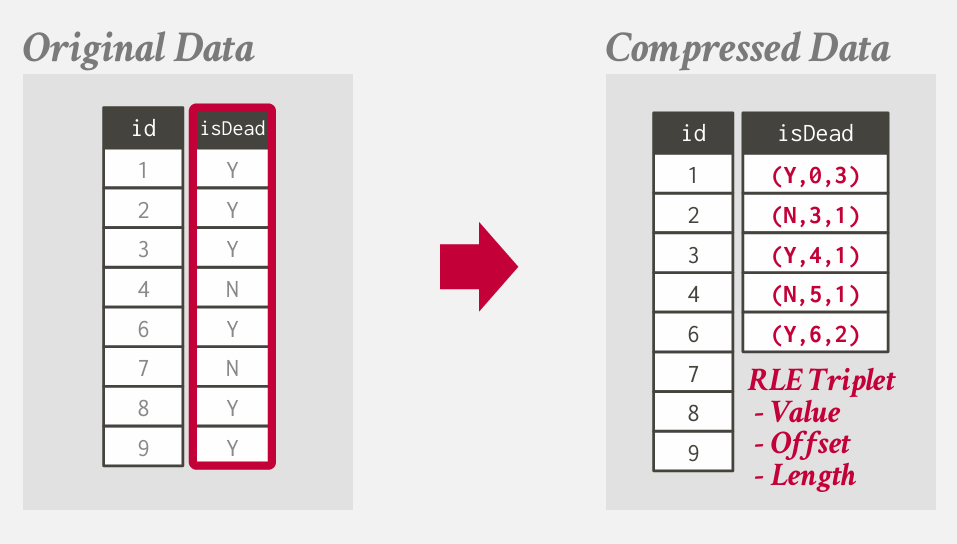
其实就是从0开始3个Y 从3开始1个N 这个意思
智能排序 会变得更好
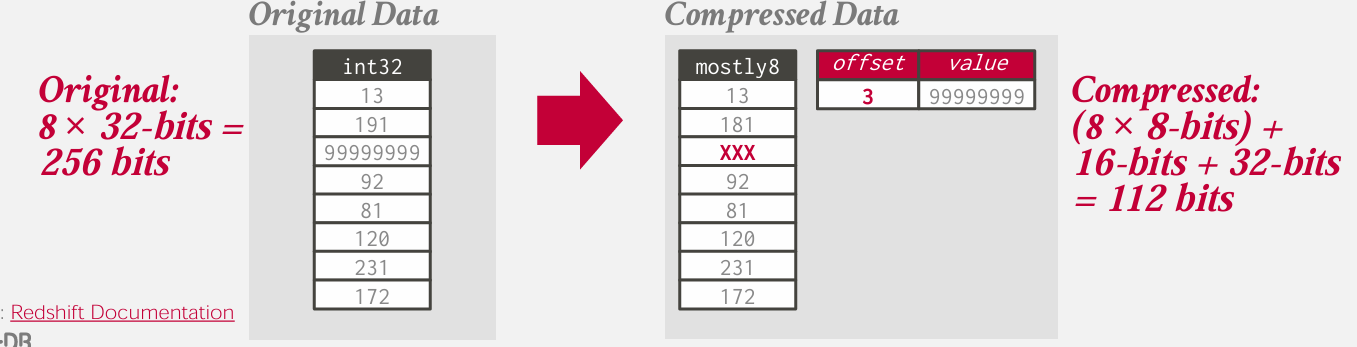
Bit Packing
这里的基本思想是 人们经常声明的属性 往往比实际要大很多
比如说 int32
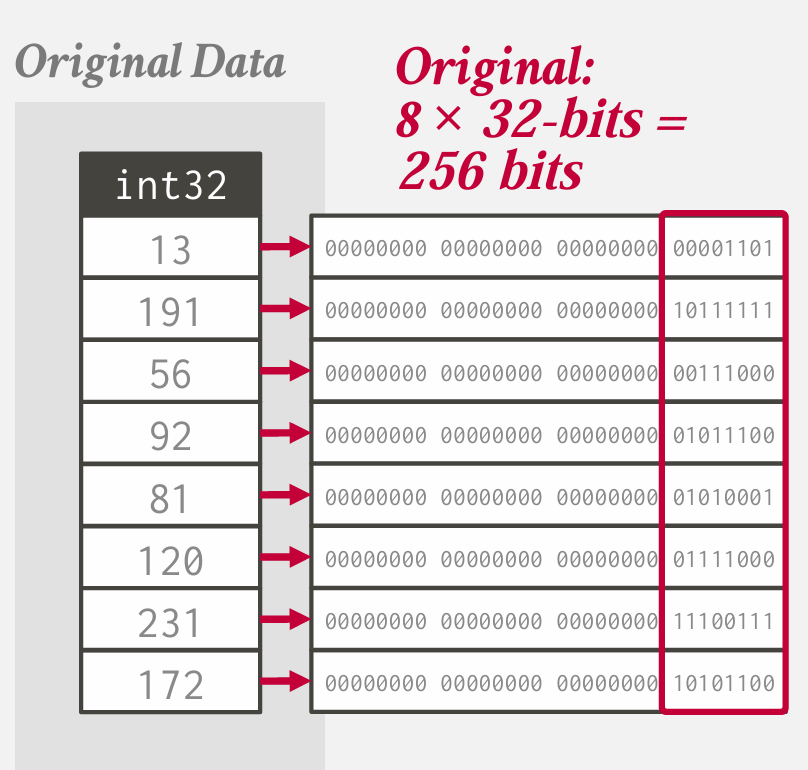

如果有一个数 没法用8bit存怎么办
无所压缩的其余值 用原始形式存储
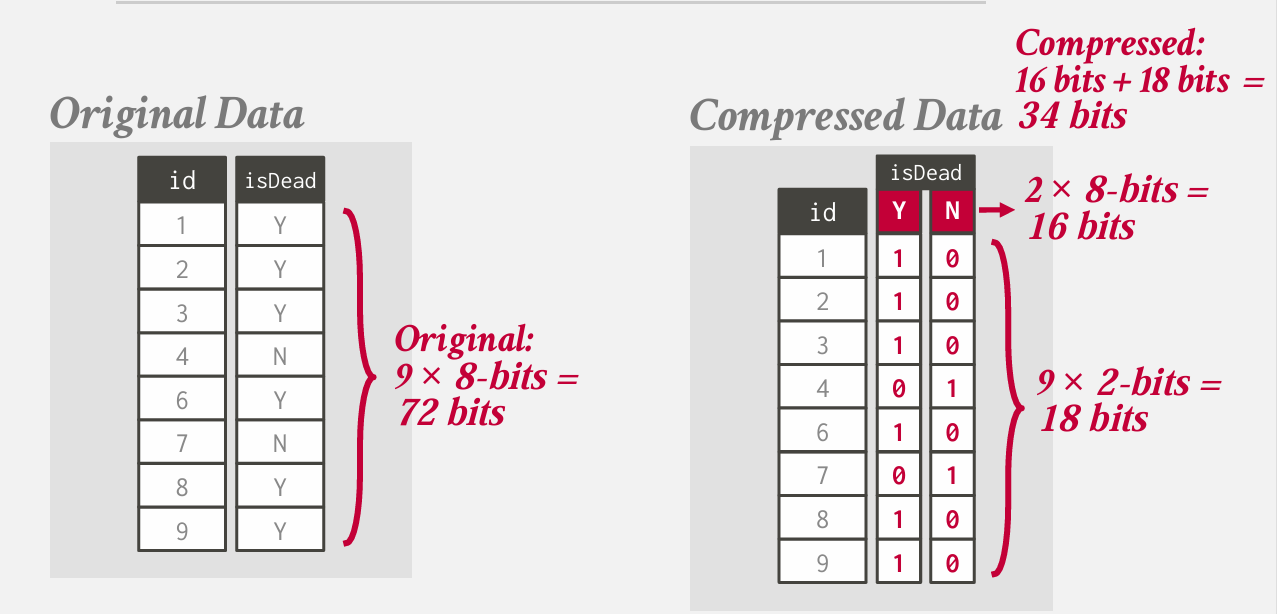
bitmap encoding
如果存在一个基数较低的属性 具有少数独特值
这时候 不在存储实际值 而是维护位图 根据向量的偏移量来确定 元组是否具有该值
有些数据库的位图索引 本质上是差不多的
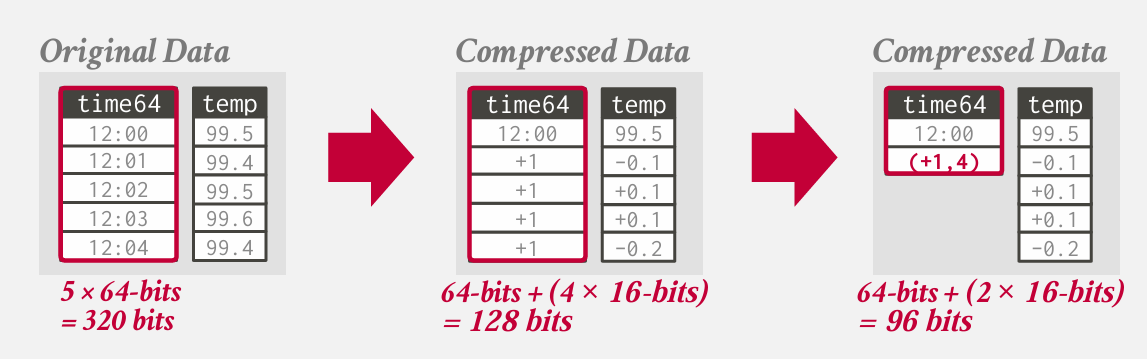
delta encoding
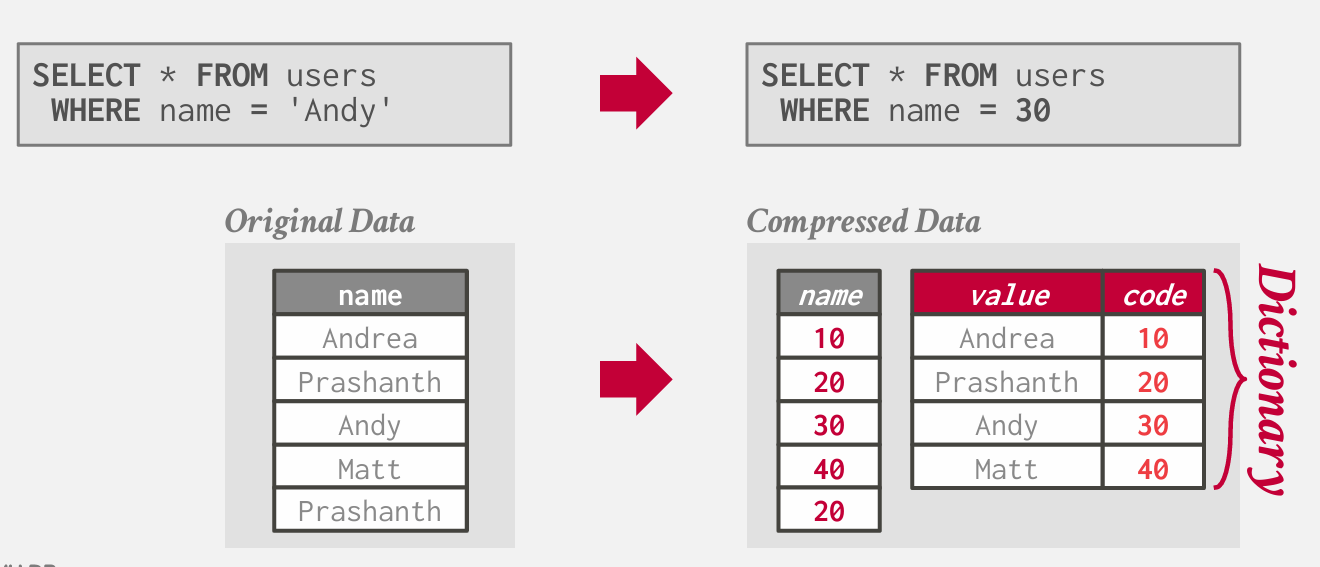
Dictionary compression
将频繁的值替换为较小的固定长度代码,然后维护从代码到原始值的映射(字典)
理想的字典方案支持对点和范围查询进行快速编码和解码
不能使用哈希函数 因为可逆哈希函数生成的结构或许比原始数据大的多
所以我们需要构建并维护一个数据结构 来实现这一功能
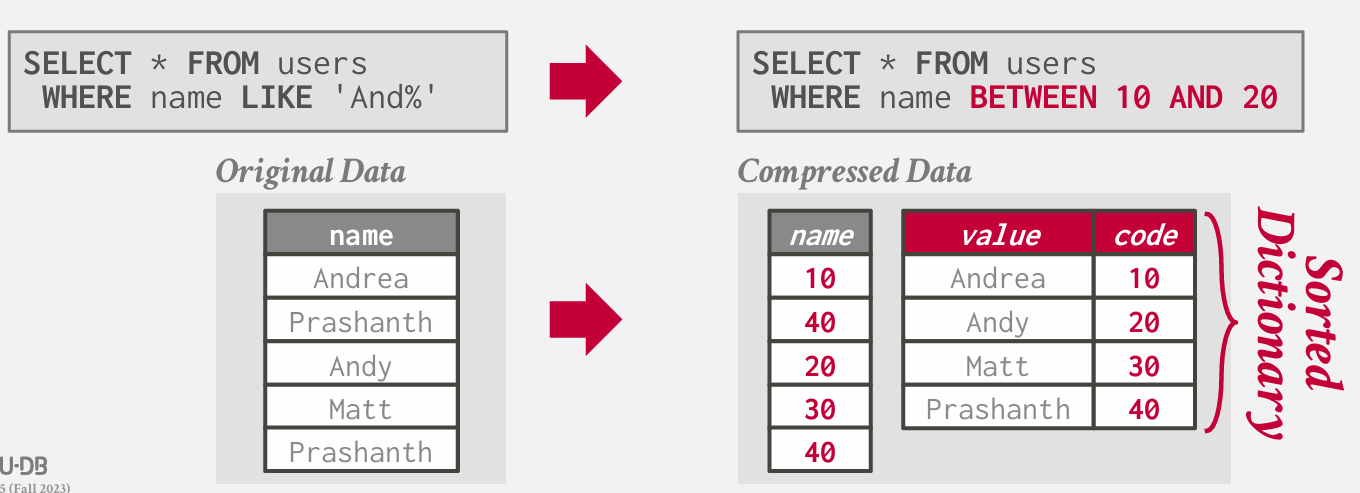
字典序
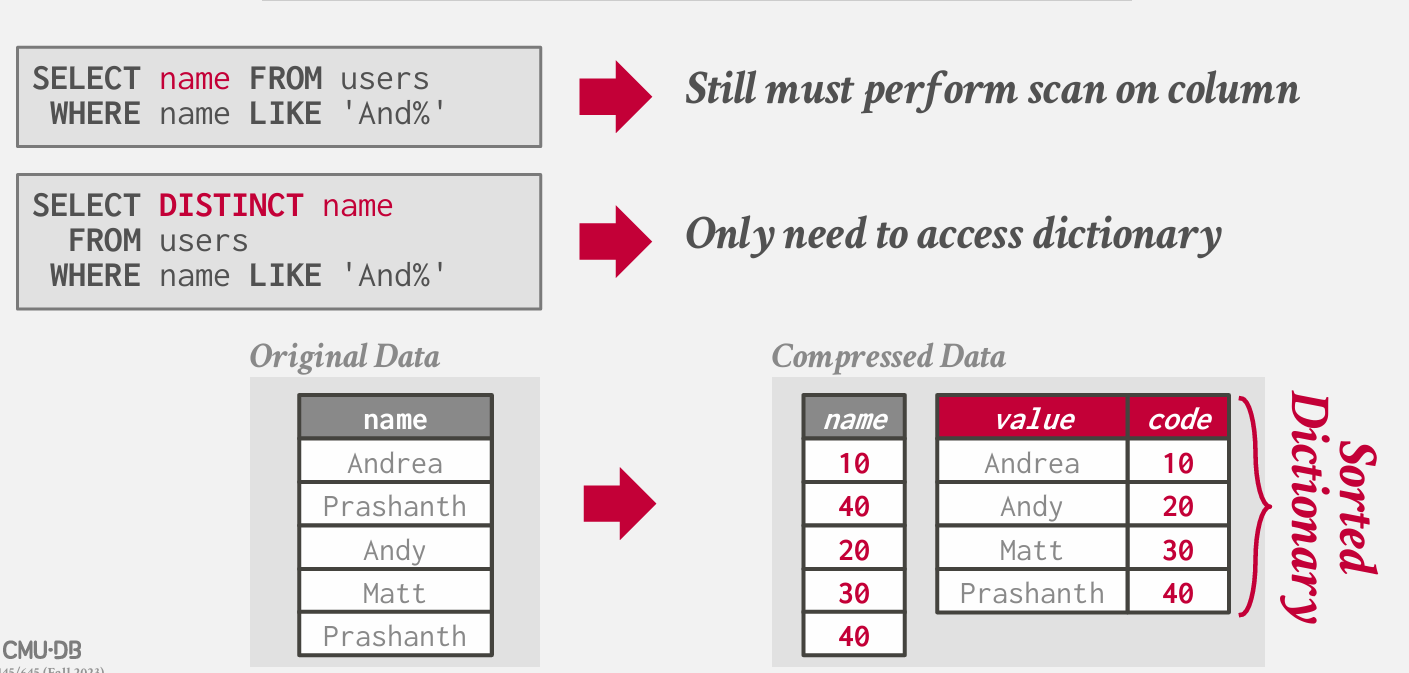
字典用什么样的数据结构?
choice 1: Array
→一个可变长度字符串数组和另一个带有映射到字符串偏移量的指针的数组。
→更新成本高昂,因此只能在不可变文件中使用
choice 2:Hash Table
-> 快 紧凑
-> 没法支持范围和前缀查询
choice 3: B+Tree
-> 比hash表慢 占用更多内存
-> 但支持范围和前缀查询
如果是不可变的 首选Array 如果可变的 b+树多一点